Data-centric applications (e.g., data analytics, machine learning, deep learning) running at HPC centers require efficient access to digital information in order to provide accurate results and new insights.
Users typically store this information on a shared parallel file system (e.g., Lustre, GPFS), which is available at HPC infrastructures. This is a convenient storage backend as it allows the same data to be used across different jobs of the same user, or even across jobs from a group of distinct users. Also, when a given job ends, while the computing resources are freed, data at the parallel file system remains persisted and accessible for future needs (e.g., analysis of results, further jobs running on top of that data).
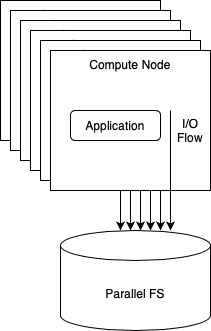
However, the downside is that hundreds to thousands of jobs concurrently access the parallel file system and compete for shared resources. This can easily lead to high variability and performance degradation and, in the worst case scenario, to completely overload the storage backend and making it unavailable.
The BigHPC project aims at solving the previous challenge by providing a new Software-Defined Storage (SDS)1 solution that can ensure better Quality of Service (QoS) for HPC storage services.
Briefly, we believe that storage I/O operations being issued by HPC workloads must be mediated by an SDS data plane stage, which can be seen as a transparent middleware “box” placed between each application and the storage resources it is using. This stage can then be used, for example, to rate limit the I/O operations being issued by a given job to avoid saturating the shared storage resources, thus improving the overall experience (QoS) for all HPC users.
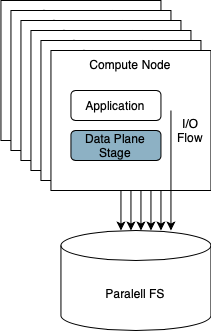
Some important questions arise from the previous design, namely:
Should this stage be deployed at the compute nodes where jobs are running or, should it be an internal component of the parallel file system?
In the project2, we are following the first approach as it promotes better portability, i.e., it can be used transparently across different file system technologies currently deployed at HPC centers (e.g., Lustre, BeegFS, GPFS).
However, it requires finding the correct interface for intercepting I/O requests from different types of applications (e.g., scientific, big data). Also, this process needs to be done transparently for these applications, as customizing the code for each distinct workload running at an HPC center is impossible.
What rate should a given stage apply to avoid saturating the parallel file system?
This is a complex question that can only be solved if the proposed solution has global knowledge about what is happening at the HPC infrastructure. Namely: i) What jobs are currently running?; ii) What is the current I/O load for each job accessing the parallel file system?; iii) Is the file system saturated?
To solve this challenge, our design also includes an SDS control plane that is able to collect monitoring metrics from the HPC infrastructure, analyze these and apply the best configuration to each data plane stage at runtime (e.g., the correct I/O rate limit to avoid saturating shared storage resources).
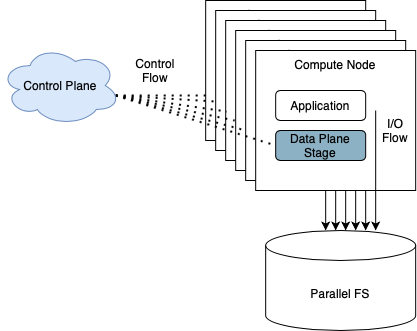
Note that the previous approach raises other important challenges that need to be addressed by BigHPC. For instance, the control plane must be able to efficiently collect monitoring metrics from thousands of nodes and jobs, to process them and to take timely decisions based on these.
Is rate limiting only useful for avoiding file system saturation?
No. Implementing rate limiting at data plane stages, and configuring it through the control plane, can also be used to ensure I/O fairness across different jobs and applications (i.e., all jobs have identical storage service level). Indeed, it can be even used to prioritize some jobs over others, for example, critical jobs that must finish first and need better performance when storing and retrieving data.
Besides rate limiting each job, are there any other complementary solutions that can also help alleviate the pressure on the share file system?
Indeed, with the previous SDS solution, one can be able to propose other storage optimizations such as data prefetching3, tiering4 (i.e., transparently leveraging local storage resources at the compute nodes where jobs are running) or data compression, which can further reduce the volume of I/O operations submitted to the shared storage backend.
We hope that you have found this post interesting and that it helped shedding a bit more of insight about the storage challenges being addressed by the BigHPC project.
João Paulo, INESC TEC
October 25, 2021
1 Macedo R, Paulo J, Pereira J, Bessani, A. A Survey and Classification of Software-Defined Storage Systems. ACM Computing Surveys, 2020
2 Macedo R, Tanimura Y, Haga J, Chidambaram V, Pereira J., Paulo J. PAIO: A Software-Defined Storage Data Plane Framework. ArXiv – Computing Research Repository (CoRR), 2021
3 Macedo R, Correia C, Dantas M, Brito C, Xu W, Tanimura Y, Haga J, Paulo J. The Case for Storage Optimization Decoupling in Deep Learning Frameworks. Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads (REX-IO), 2021
4 Dantas M, Leitão D, Correia C, Macedo R, Xu W, Paulo J. Monarch: Hierarchical Storage Management for Deep Learning Frameworks. Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads (REX-IO), 2021