The last decade witnessed a new era of software development that allows software developers to write applications independently of the target environment by packaging them along with their dependencies and environment variables inside containers. Numerous studies [1-2] have shown that containers are optimal for building and running applications reliably on diverse computing infrastructures, leading to improved developer productivity and broader deployment of the applications.
Containers have now become ubiquitous. They are used in public and private clouds and High Performance Computing (HPC) infrastructures that boast a massive amount of computing resources with high computing power and storage capabilities distributed across a high-speed network. The challenge lies in supporting Big Data applications along with the traditional HPC applications on top of heterogeneous HPC hardware while ensuring the performance and availability requirements of the different applications are met.
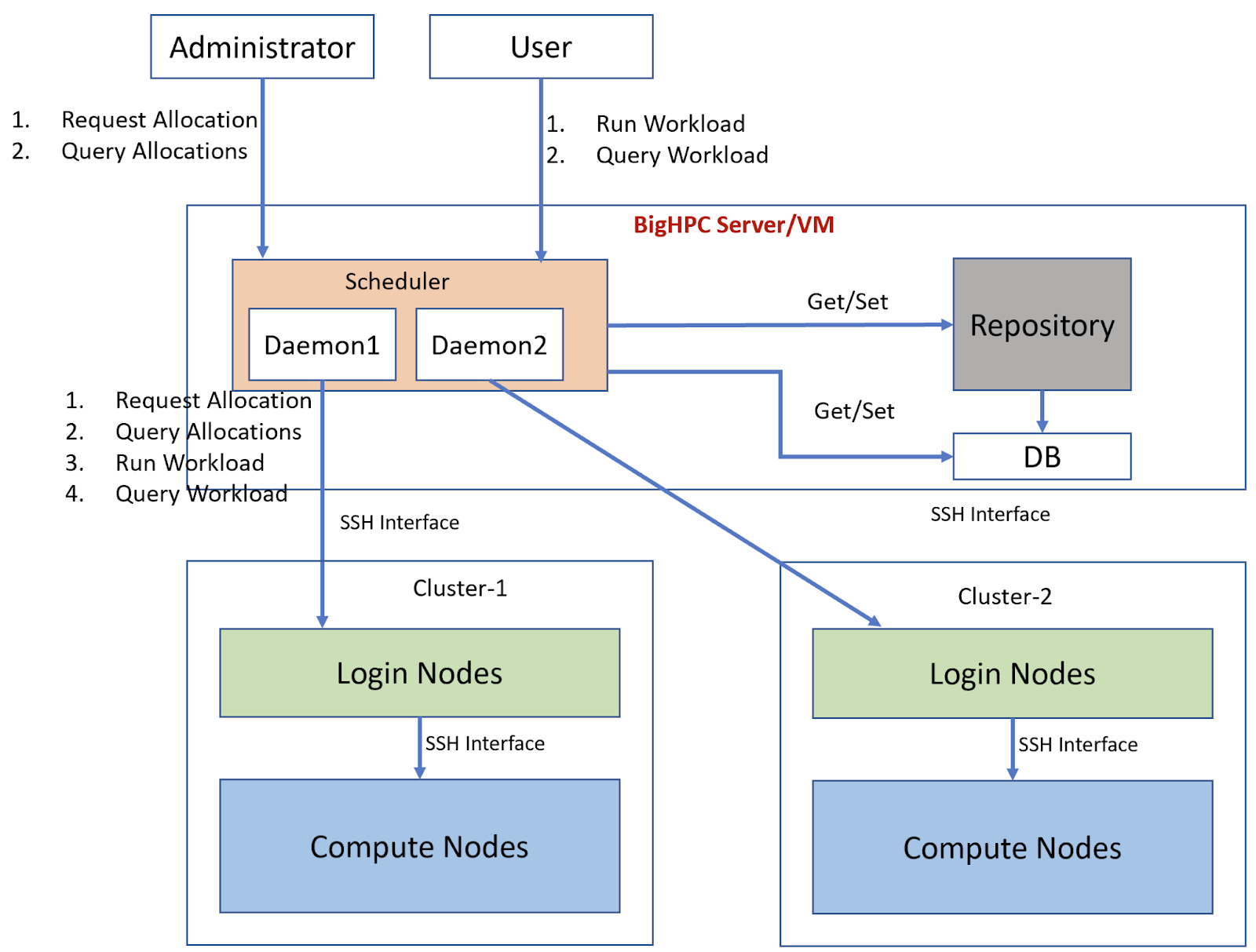
On BigHPC platforms, the Orchestrator layer contains the “Virtual Manager (VM)”, which is responsible for abstracting the heterogeneous physical resources and low-level software packages (e.g., compilers, libraries, etc.) that currently exist in an HPC cluster and provides a common abstraction that allows both HPC and Big Data applications to be easily deployed. Virtual Manager performs three main functions viz:
1) controls the BigHPC allocation of nodes on the host HPC system on which the BigHPC workloads execute;
2) provides the interface through which BigHPC users submit and monitor their workloads;
3) and determines when and where workload requests execute by comparing the workload resource requirements and QoS specified by the user with the available resources and QoS reported by the BigHPC Monitoring and Storage Manager components respectively.
The Virtual Manager includes a repository that stores container templates and actual container images and a scheduler that optimally schedules workloads on BigHPC reservations as per their resource requirements. A background daemon continuously evaluates the incoming or pending requests, reserves/tears-down the computational resources on HPC infrastructure, executes the workloads in queue order, and makes the workload execution results available to the user.
In practice, there could be two main approaches to designing Virtual Manager. In the first approach, Virtual Manager is implemented as Kubernetes, which provides a well-established mechanism to orchestrate containers on computing resources. In HPC, the Kubernetes implementation involves running a kubelet on each compute resource that notifies its existence and performance metrics to the Kubernetes server running remotely on the BigHPC machine. This approach necessitates a container runtime running in the background on computing resources which is not viable as it demands administrative access, which is hardly available on HPC compute nodes. The second approach is more like a traditional client-server approach that involves writing entire container orchestration through a web server running on a BigHPC machine and web clients running on compute nodes. This BigHPC specific approach is versatile to implement, easy to maintain, and flexible to leverage the heterogeneous and upcoming HPC resources. This approach does not demand administrative privileges on compute nodes but mandates an open web connection to the BigHPC machine from compute nodes.
We plan to implement the Virtual Manager in conjunction with a time-series database and verify it with benchmarks, scientific, machine learning, and cloud applications. Currently, the Virtual Manager is under development. We have performed pilot studies using the High-Performance Linpack (HPL) Benchmark implemented with the Charliecloud containerization technique and run on HPC compute nodes from Virtual Manager. Going forward, we will extend the VM framework with additional features and test exhaustively for correctness and performance.
References
[1] Amit Ruhela, Stephen Lien Harrell, Richard Todd Evans, Gregory J Zynda, John Fonner, Matt Vaughn, Tommy Minyard, John Cazes. Characterizing Containerized HPC Applications Performance at Petascale on CPU and GPU Architectures. In: Chamberlain, B.L., Varbanescu, AL., Ltaief, H., Luszczek, P. (eds) High Performance Computing. ISC High Performance 2021. Lecture Notes in Computer Science(), vol 12728. Springer, Cham. https://doi.org/10.1007/978-3-030-78713-4_22
[2] A. J. Younge, K. Pedretti, R. E. Grant and R. Brightwell, “A Tale of Two Systems: Using Containers to Deploy HPC Applications on Supercomputers and Clouds,” 2017 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), 2017, pp. 74-81, doi: 10.1109/CloudCom.2017.40.
Amit Ruhela, Stephen L. Harrell, John Cazes, Texas Advanced Computing Center
June 20, 2022