The gap between the developers’ environment and the complexity of BigHPC infrastructure brings a challenge that can be solved by joining together teams that normally have different perspectives. The developers and infrastructure managers provide the experience required to understand the software delivery and operation tasks, but lack the contract to provide the deployment. The DevOPS methodology focuses on the deployment of developed software and is elected as the main practice during this activity, fixing the missing brick between development and Information Technology (IT) operations.
Why GitOPS?
GitOPS is a way to implement the continuous deployment and software quality best practices. Using a GitOPS framework solution put into practice the methodology advantages, such as:
- deploy faster and more often
- easy and fast error recovery
- easier credential management
- well documented deliveries with complete history of every change made to the system
- share knowledge between teams with great commit messages
As a result, everybody would be capable of reproducing the tough process of changing the infrastructure and also easily find examples on how to set up new systems.
In this work, git workflow is being adopted for application development. Supporting that process, we are preparing the required the tools to answer the three components of GitOPS:
- infrastructure as code
- merging changings together
- deployment automation
The adoption of this approach brings multiple advantages, such as, improving the technical capabilities, adopting good practices and pursuing fast innovation delivery. Developers should be kept focused on the continuous development of the software. The IT operations team is responsible for the infrastructure management.
Gitlab as the frontend for the development platform
Using the Gitlab platform it is possible to get all output from jobs along the submitted code, keeping the complete report of the development. This will allow the developer to save time avoiding the access to the infrastructure and focus on code development. At the same time, this will bring together the system administrator to help troubleshoot the issues with complete logs of all tests and, if applicable, create a docker image with all tools and dependencies required to run and test the software taking into account the particularities of each environment.
Gitlab platform also supports CI pipeline and, to start reviewing the BigHPC platform deployment, the pipeline as code (PaC) example begins with the pipeline template with the draft in figure 1:

Figure 1: Gitlab pipeline template preview
This pipeline has the required stages to test the code, test the BigHPC in the defined testbeds environments and deploy the pilot:
- Build: build container images, compile required code.
- Development: Unit testing, linting (code style checks), static security tests.
- Preview: Integration tests, functional tests, dynamic security tests.
- Production: Delivery to production (create a release), automated deployment.
Afterwards it is possible to check the job logs that are sent by a gitlab runner while it’s processing a job (figure 2). This allows easier interaction between the developer and the runtime results, saving time to other development tasks.
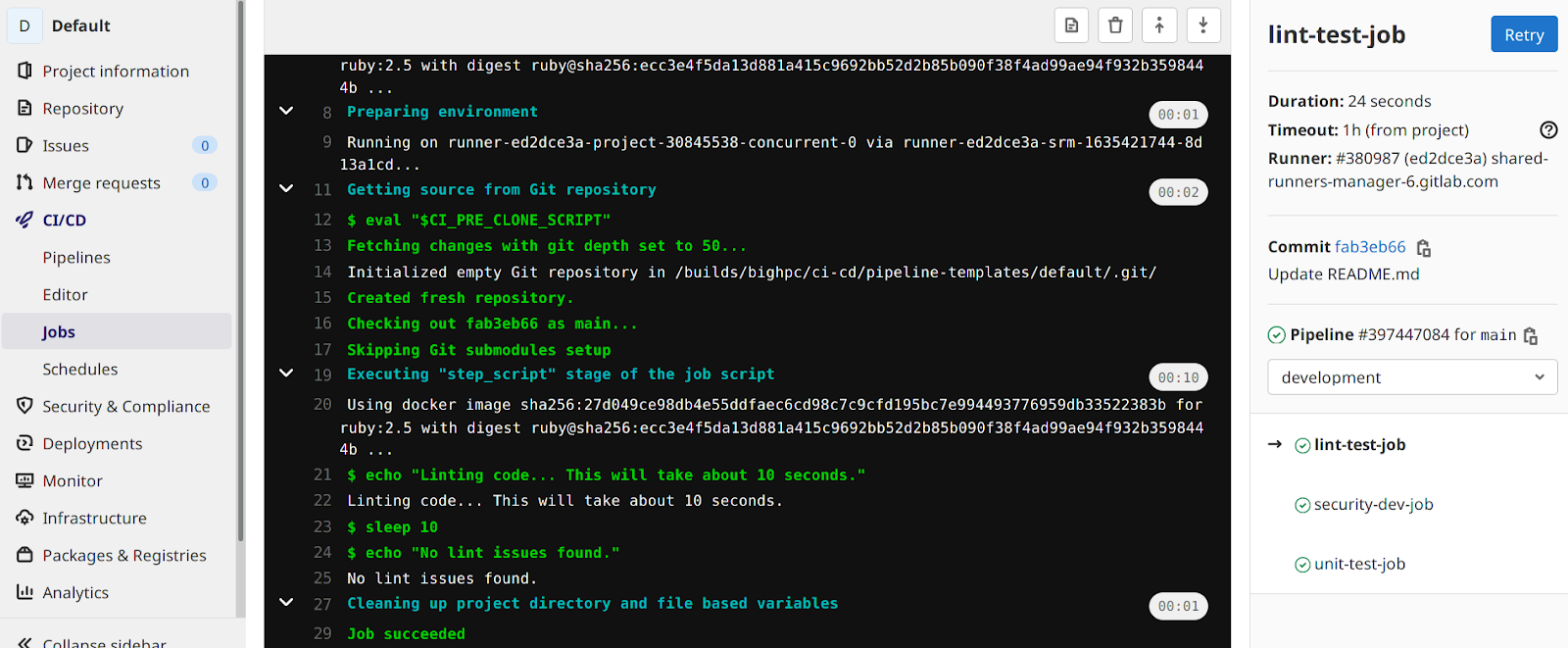
Figure 2: Check the job logs after selecting a Gitlab job
Services deployment
GitOPS implementation keeps all deployment code maintained as configurations in a git repository. This puts together two main ideas: the deployment strategy and the system for automating deployment, scaling, and management of applications.
For deployment strategy, the preferred one is pull-based (figure 3) because it is considered the more secure and thus better practice to implement GitOps. Traditional CI/CD pipelines are triggered by an external event, for example when new code is pushed to an application repository. With the pull-based deployment approach, the operator is introduced. It takes over the role of the pipeline by continuously comparing the desired state in the environment repository with the actual state in the deployed infrastructure. Whenever differences are noticed, the operator updates the infrastructure to match the environment repository. Additionally the image registry can be monitored to find new versions of images to deploy.
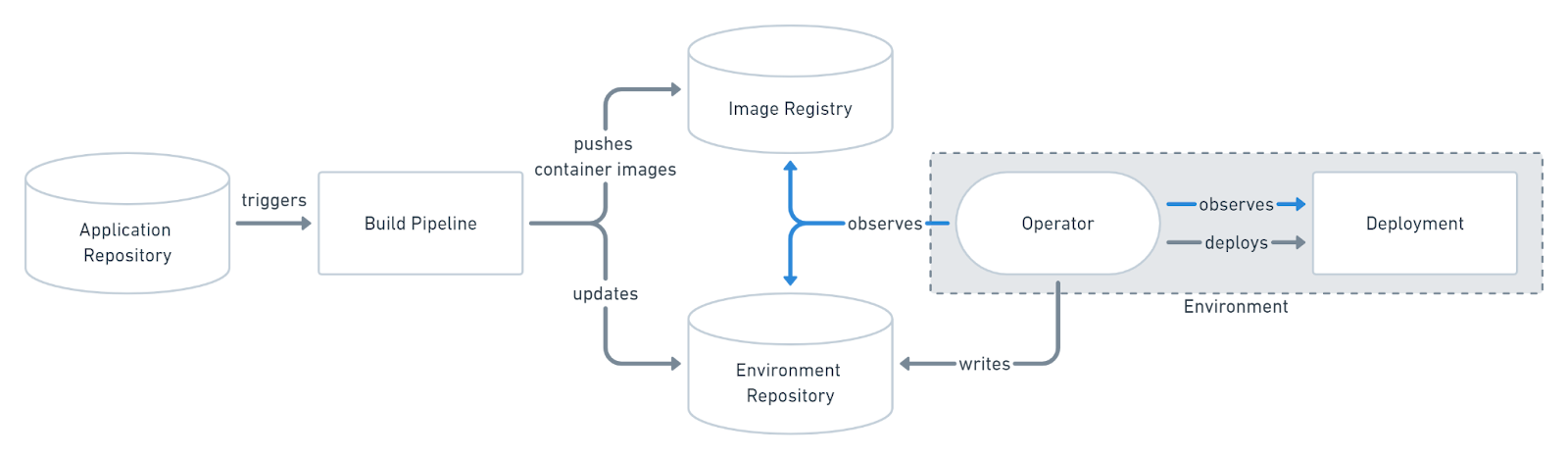
Figure 3: Pull-based deployment strategy
Implementations for pull-based deployment strategy are available with Gitlab Agent and ArgoCD. Gitlab Agent is a recent implementation and lacks some limitations when compared with ArgoCD. Argo CD is implemented as a kubernetes controller which continuously monitors running applications and compares the current, live state against the desired target state (as specified in the Git repository). Argo CD reports and visualizes the differences, while providing facilities to automatically or manually synchronize the live state back to the desired target state. Any modifications made to the desired target state in the Git repository can be automatically applied and reflected in the specified target environments.
ArgoCD also provides a web interface where it is possible to check the health status of application resources and the application activity at realtime (figure 4).
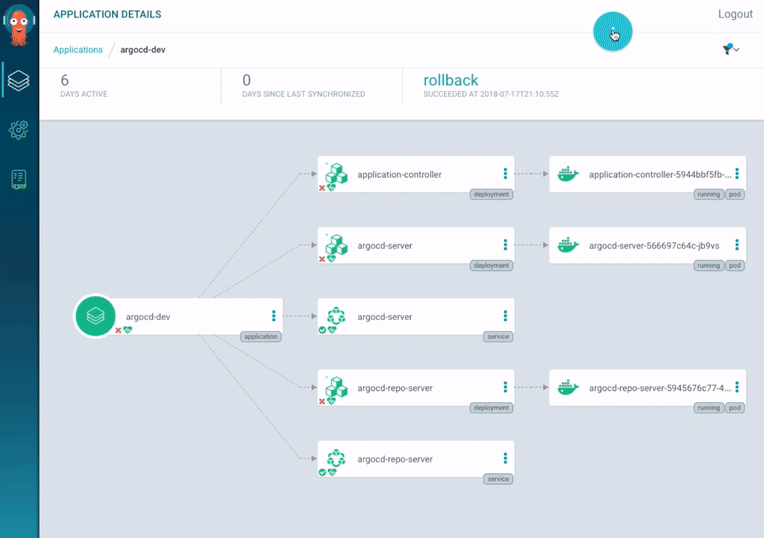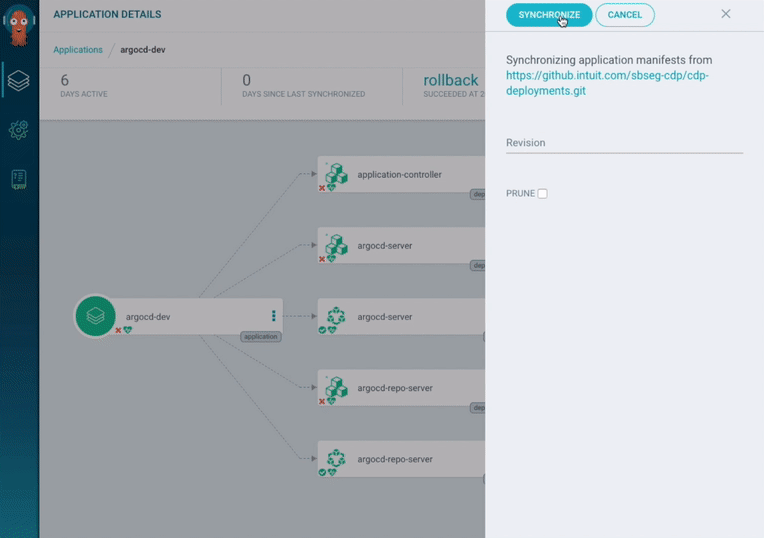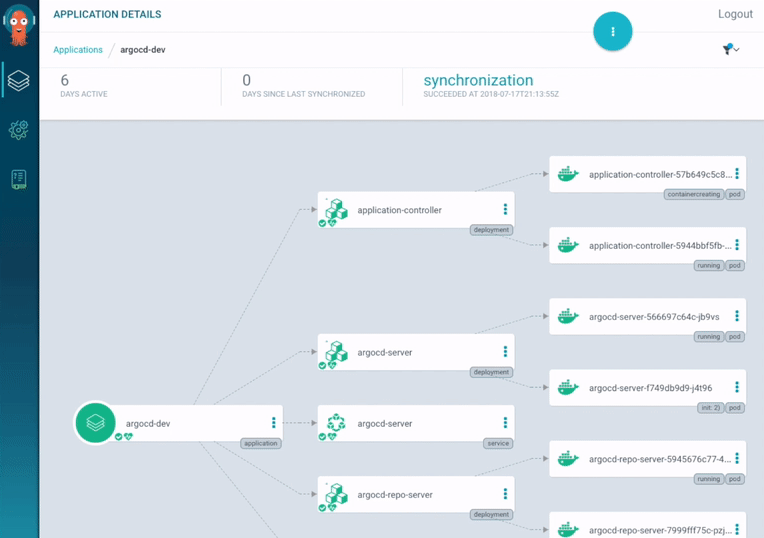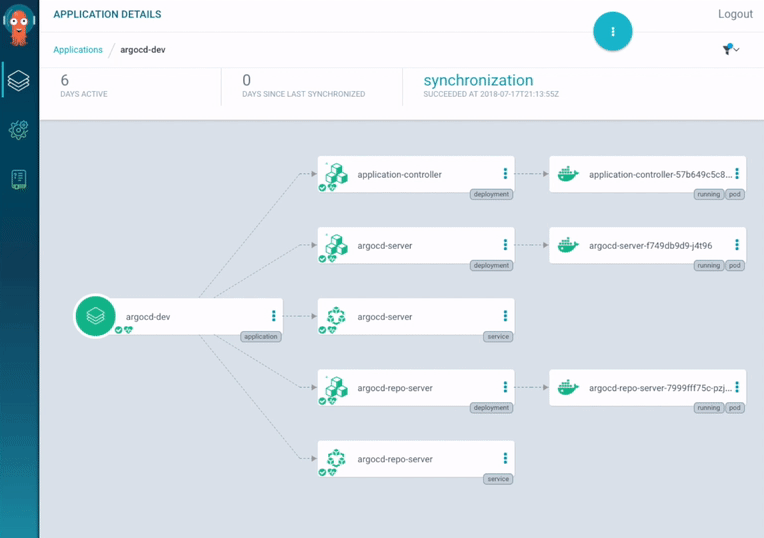
Figure 4: ArgoCD application dashboard
Either Gitlab Agent or ArgoCD requires a Kubernetes system already installed. Kubernetes defines a set of building blocks (“primitives”) that collectively provide mechanisms that deploy, maintain, and scale applications based on CPU, memory or custom metrics. Kubespray is used to orchestrate the deployment of a kubernetes cluster, supporting multiple cloud providers.
What’s next?
We hope this article has piqued your interest in the topic of GitOPS and that it might motivate you to take the first step to try it out. Please feel free to contact us for any doubt.
Samuel Bernardo and Miguel Viana, LIP
December 22, 2022


