Following the challenges addressed in our first blog post, BigHPC will design and implement a new framework for monitoring and managing the infrastructure, data and applications of current and next-generation HPC data centers. The proposed solution aims at enabling both traditional HPC and Big Data applications to be deployed on top of heterogeneous HPC hardware. Also, it will ensure that resources (e.g., CPU, RAM, storage, network) are monitored and managed efficiently, thus leveraging the full capabilities of the infrastructure while ensuring that the performance and availability requirements of the different applications are met. In this blog post, we want to briefly describe each of the main components and interfaces of this novel framework.
The framework will enable HPC users to deploy their Big Data applications as containerized jobs through a Deployment interface. Then, by resorting to a Management interface, system administrators will be able to manage the overall infrastructure and deployed applications (e.g., to manage the lifecycle and placement of containers). Moreover, both users and system administrators will have access to a console with the overall status of cluster resources and applications deployed on these.
Now, let us focus on the three main components provided by BigHPC.
The Monitoring Backend will collect resource usage metrics (e.g., CPU, RAM, network and storage I/O) from containers deployed at the HPC infrastructure. Short-term and long-term metrics will be collected at different granularities, namely at the job/container level and at the compute node level. Furthermore, the Monitoring component will have access to general I/O metrics provided by the HPC’s parallel file system (e.g., Lustre file system).
Besides exporting metrics through the web interface, the Monitoring solution will provide an internal monitoring API so that the other two main components, which we describe next, can also have access to these metrics.
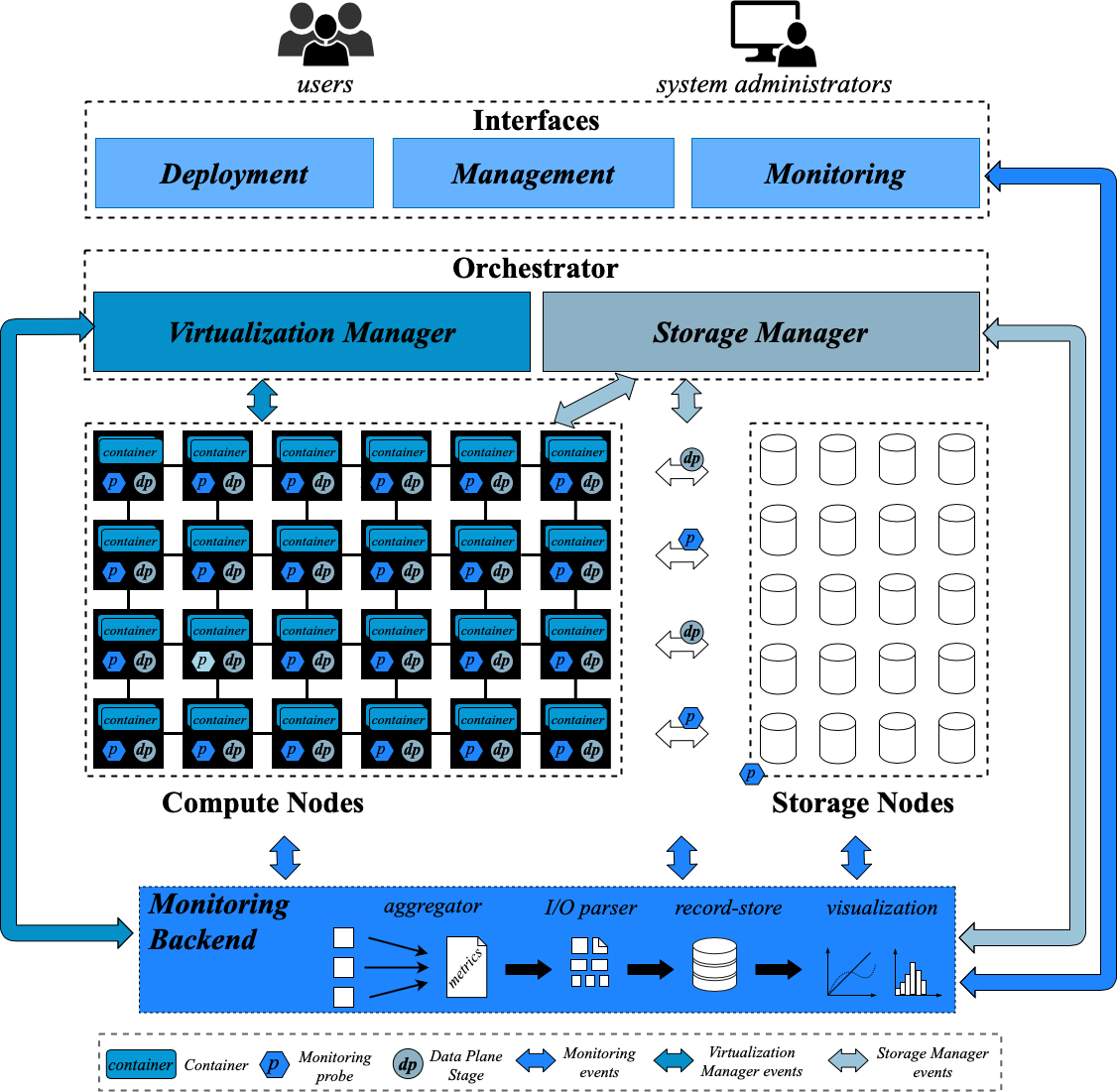
BigHPC’s framework overview
The Virtualization Manager is responsible for abstracting the heterogeneous physical resources and low-level software packages (e.g., compilers, libraries, etc) that currently exist in an HPC cluster and to provide a common abstraction so that both HPC and Big Data applications can be easily deployed on such infrastructures. To achieve such a goal, this manager will resort to virtual containers. Containers will be running user applications in an isolated fashion and their placement, across the computational nodes, will take into account the performance and reliability requirements of each application while providing optimized usage of the infrastructures’ overall resources (i.e., CPU, RAM, network, I/O, energy).
The Storage Manager will ensure optimized configuration of shared storage resources provided to applications and jobs running at the HPC infrastructure. This component will follow a Software-Defined Storage approach while providing the building blocks for ensuring end-to-end control of storage resources in order to achieve QoS-provisioning, performance isolation, and fairness between HPC containers (Big data applications).
The Storage manager will decouple the control and data flows into two major components, control and data planes. The data plane is a programmable multi-stage component distributed along the I/O path that enforces fine-grained management and routing properties dynamically adaptable to the infrastructure status (e.g., rate limiting, I/O prioritization and fairness, bandwidth aggregation and flow customization). Such a component will be employed over containers and compute nodes at the HPC infrastructure and will manage the storage I/O flows to local storage mediums available at each compute node and the shared storage backend (e.g., Lustre file system). The control plane comprehends a logically centralized controller with system-wide visibility that orchestrates the overall storage infrastructure (i.e., data plane stages and storage resources) in a holistic fashion. The control plane is scalable and enforces end-to-end storage policies, tailored for attending the requirements of exascale computing infrastructures.
We hope that this post has shed some light about the vision and design of BigHPC. Stay tuned for the next blog posts where we will address and further detail the project’s contribution for each of the main components.
BigHPC Consortium
August 9, 2021